有两种角度看待寄存器机器:其一更关心 CPU 解码执行的指令,其二则更执着于数据是如何流过指令产生变化的。程序语言作为对计算机操作的抽象,大体也分为这两种流派:命令式编程语言以及其变体 —— 面向对象思想(C、SmallTalk)和函数式编程语言(LISP、Haskell)。
编程语言中的抽象基石 —— 函数可以看做“指令”动作的集合,其包含一个输入、若干条指令、一个输出,通过对指令的封装和对函数的重用以形成黑盒,这种称之为 API 的约定允许开发者站在巨人的肩膀上更快、更好的操纵冯诺依曼程序存储计算机器,因此计算机的应用迅速普及开来。在函数式阵营,由于强调数据的流动,因此函数式编程语言中的函数更纯粹,正交性更高,也更容易进行高层次抽象,虽然二者在功能上是等价的,但执行效率却没有命令式的高,因此当今计算世界的大部分基础设施多是命令式语言写就的:C 和 C++ 之于操作系统、数据库、浏览器等。
而随着摩尔定律失效,多核心计算机的普及以及算力的提升,命令式模型中,多线程间为了性能而不可重入的函数抽象、多进程通过共享内存交互在并行编程中难以保证数据安全,虽然现代命令式语言大多引入了函数式特性来保证函数的可重入性(Rust、Scala、Swift、Kotlin、现代 Java:默认不可变的“变量”,作为一等公民的简单函数),并且在开发者之间约定了大量的规则(不使用全局变量等),但真实世界总有一部分是可变的,因此也诞生了很多技术用于解决这一问题:锁、CAS 算法,STM,异步回调,但并行编程的复杂度还是太高,以此开发的程序很容易带有缺陷或难以维护。
是时候回归函数式语言的本质了:更多关注数据而非指令。基于这种思想,传统的线程被协程(更轻量:调度切换时间和内存开销更小)所取代,传统的通过加锁共享内存和保证函数顺序调用来互相通信被消息传递(即所谓的同步和异步,函数调用的同步指的是数据从参数“发送”,从返回值“获取”,这个过程是阻塞等待的,消息传递的异步指的是数据总是单向的从一个实体到另一个实体,其不等待回复,而是等待未来另一个实体给自己回复消息)所取代,换言之,在时间和空间上进行解耦。这种思想有很多类似实现:Erlang/Scala/Clojure 中完全基于消息通信的 Actor 模型(Scala Akka,Clojure Agent),Go/Clojure Async 中类似的协程和带缓存/不带缓存通道 —— 带缓存在时间空间上解耦,不带缓存在空间上解耦,模型相对简单且保持了灵活性。Actor 相当于每个实体都带有无穷个队列 —— 信箱,其模型复杂却更灵活。需要注意的是,函数调用也有可能是异步的,即返回所谓的 Future,但这种异步和消息传递的异步不同,其麻烦事依旧很多:比如 JavaScript 异步回调地狱,虽然异步函数调用的改进方案:async/await 解决了回调地狱,但依旧无法很好的处理多线程/协程安全通信的问题,Future Monad 也解决了回调地狱,并通过手动在多个线程/协程间传递消息 CPS 解决了线程/协程通信,但 Monad 类型系统过于死板且不灵活,数据被禁锢住了。函数调用的异步并不是真正对于数据的关注,依旧是以指令为中心的处理逻辑,其充其量是在时间上进行解耦,模型最简单但灵活性最差。
在网络应用和分布式环境中,同步的函数调用现在化身为 RPC 远程过程调用以实现空间解耦,其面临的问题和函数调用没有什么区别。而在这样的环境下,消息通信也不是能够无限横向扩展的“灵丹妙药”,和很多业务问题的逻辑并不相同,Akka 的消息通信不能保证消息传达的可靠性,尤其是在分布式环境下,因此需要在业务层做大量的工作(这恐怕也是 Go goroutine 仅限于单机的原因)。而现有的主流办法,就是让数据系统和业务系统分离,业务系统纯粹且可以横向扩展,而不同节点的通信则交由数据系统负责——大多通过事务完成,这种解决方案导致了数据库经常成为拖累可扩展性的源头。为了解决这一问题,开发者们又引入了分布式缓存 —— Redis,其能够在分布式环境中通过缓存减缓一些数据库的压力,而对于节点通信则通过实现分布式锁以重复在单机环境下共享变量和保证函数顺序调用那一套。而另一种解决办法,则是引入分布式消息系统 —— kafka,其相当于分布式系统中可靠的带有缓存的可重复使用的 Clojure Async 通道/Goroutine 通道。在完全着眼于数据的“大数据系统”中,Kafka 已经成为事实上的标准,而在同步教信徒(或者那些从来没有真正按照函数式语言思想认识程序的人)的眼中,Kafka 也成为一个能够大幅减缓数据系统压力、将各个组件在时间和空间上解耦的神兵利器(生产者可以一次性大量生产数据,而数据库可以慢慢消费数据):用于日志、行为等单向数据流的消费,或者用于数据提交处理,之后推送给用户结果/等待用户自行刷新。但 kafka 唯有在异步系统架构中才能完全发挥实力:想象一下可扩展的前端应用网关,消费者等待前端生产的数据被后端数据系统慢慢消费后异步的生产信息并消费最终返回,这种模式对客户而言是同步等待,但对应用系统而言则是异步(就像接待员和后厨大厨生产,接待员不够可以再招,接待员和后厨的异步意味着没有任何崩溃会发生)。
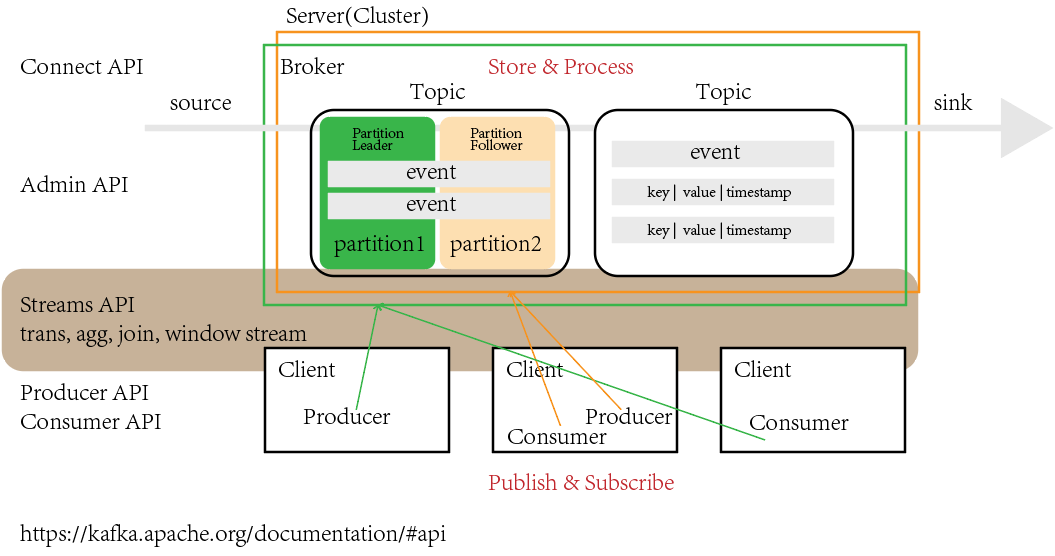
总的来说,Kafka 是一种事实标准的消息中间件,其包含三个特性:分布式队列、持久化缓存、发布/订阅模式,分布式队列意味着其可用于异步开发,持久化缓存意味着其可以实现可靠数据中转及灵活数据消费,发布/订阅模式则将消费者和生产者彻底解耦,让其应用场合更加广泛。这些特性:基于发布/订阅模式的带有持久化缓存的分布式队列,让 Kafka 比传统产品:RabbitMQ 等更受欢迎。